

Last spring, we onboarded a Series B client who arrived with a beautiful ICP document. Forty slides. Quotes from customer interviews. Persona cards with stock photos and aspirational job titles. The marketing team had built it the previous quarter, and the SDR team had been working off it ever since. It was a genuinely thoughtful piece of work, and it had been useful for human reps.
We tried to feed it to the agent system, and the agent fired blanks for a week.
The document said things like our buyer is a forward-thinking VP of Operations at a mid-market company who values efficiency and is open to new technology. A human SDR could read that, file it under context, and write a decent first email. The agent could not. It needed structured criteria that it could query against actual companies. It needed to know which signals mattered, weighted against each other. It needed a definition of who the ICP was not. It needed thresholds and tradeoffs encoded as logic, not vibes.
We rebuilt the ICP from scratch in the next two weeks. Same buyer. Different document. The agent system started producing a pipeline by week three.
This post is about that difference. What an ICP needs to look like when an autonomous agent is going to consume it, why most existing ICP documents fail that bar, and how to build one that works before you wire up any agents at all.
Check the full agent system run on a real ICP: the autonomous agents pipeline demo at Tech Week Boston.
Human-grade ICP and machine-grade ICP are not the same document

Most ICP work in B2B has been done for human consumption. The buyer of the document is a sales rep or a marketer; the goal is shared understanding, and the format reflects that. Persona cards. Narrative descriptions. Quotes. Aspirational language. The a16z framework for ICP is one of the better generic versions, and it is still written for humans to read and apply judgment.
The frameworks are not wrong. They are just incomplete for a different job. The job that needs to be done for an autonomous pipeline system is not a shared understanding. It is a structured selection. The agent has to look at a list of ten thousand companies, score each one against your ICP, return a ranked list, and then look at the buying committee inside each top-ranked account and do the same exercise for contacts. Every step requires the ICP to exist as queryable data, not as a paragraph.
This is the gap most teams hit when they try to build agent infrastructure on top of their existing ICP documentation. The doc was written for people. The agent is not a person. The translation does not happen automatically, and skipping it is the single most common reason early agent deployments produce no pipeline.
The four properties of an agent-grade ICP
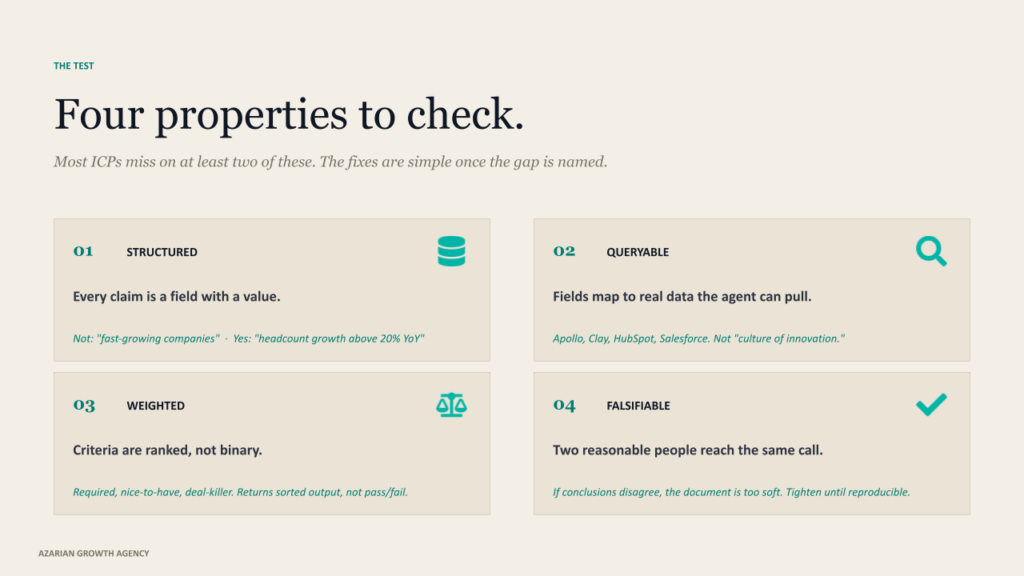
When we sit down with a client to rebuild their ICP for an agent system, we are essentially testing the existing version against four criteria. Most ICPs miss on at least two of them. The fixes are usually simple once the gap is named.
Structured. Every claim in the ICP has to be expressible as a field with a value. Industry, size, revenue band, tech stack, hiring patterns, geography. The agent reads structured data and returns structured outputs. A line in the doc that says we sell to fast-growing companies is useless. A line that says headcount growth above 20% YoY based on LinkedIn data is something an agent can actually query.
Queryable. The fields have to map to data sources that the agent can actually pull from. Apollo, Clay, HubSpot, Salesforce, whatever the source is. If a criterion in your ICP is not retrievable through any tool the agent has access to, it is functionally invisible to the agent. We have seen ICP documents that included things like the company has a culture of innovation. That is real, that probably matters, but no agent in 2026 can score it.
Weighted. Not all criteria are equal. Some are required, some are nice-to-have, some are deal-killers. The ICP has to make those weights explicit so the agent can rank rather than just filter. A binary pass-or-fail ICP returns either too many accounts or too few. A weighted ICP returns a sorted list with the highest-fit accounts at the top, and that is the input that downstream agents in the chain need to do their work.
Falsifiable. You should be able to look at any account and say with confidence whether it fits or does not. If two reasonable people read your ICP and reach different conclusions about the same account, the document is too soft. The agent cannot make a call that your humans cannot make. Tighten the criteria until the conclusion is reproducible.
The ICP is not a description of your buyer. It is the configuration file your pipeline system runs on.
Where the real ICP actually lives
Here is the thing nobody tells you when they hand you an ICP framework. The ICP is not in the marketing slides. The ICP is in your closed-won data. The teams that produce the strongest agent-grade ICPs do not start by interviewing their team about who the customer should be. They start by looking at who the customer actually is.
The exercise we run with clients is what we call a closed-won audit. Pull the last 24 months of closed-won deals. Tag each one with structured fields: industry, employee count, revenue, geography, tech stack at time of purchase, source channel, sales cycle length, deal size, expansion within 12 months. Then look for the patterns that actually predict close-won, not the ones the team thinks should predict it.
What you usually find is interesting. The customers the team thinks they sell to and the customers they actually sell to are not the same set. The sales cycle is twice as long for the wrong-fit accounts. Expansion revenue concentrates inside a specific subsegment nobody had named. Deal size correlates more strongly with one technographic signal than with all the firmographic filters combined.
This is not a survey exercise. It is a data exercise. We have written elsewhere about how AI-driven customer insights accelerate this kind of pattern-finding, but the principle holds even with manual analysis. Closed-won is the ground truth. Everything else is a hypothesis.
Once you have the patterns, you reverse engineer them into structured criteria. The fields, the weights, the thresholds. That is the spine of the ICP your agents will run on, and it is dramatically different in shape from the ICP a marketing team would write from scratch.
The negative ICP, almost no team writes down

If the closed-won audit is the part most teams underweight, the negative ICP is the part most teams skip entirely. And it is the part that produces the biggest immediate lift when you add it to an agent system.
A negative ICP is the explicit list of who you do not sell to and why. Not the absence of fit. The active disqualifier. The industries where the regulatory environment makes your product unworkable. The company sizes where the procurement cycle eats into the margin.
The geographies where the support model breaks. The tech stacks where the integration is a six-month project nobody will fund. The buyer titles where the political dynamics mean you will lose to incumbent vendors, no matter how good your pitch is.
Most teams have this knowledge. It lives in the heads of the AEs who have lost the deals. It almost never lives in the ICP document. When you build an agent that scores accounts against a positive-only ICP, the agent dutifully scores those disqualified accounts as moderate-fit because they pass most filters. Your reps then waste cycles on prospects everyone on the team already knew were dead on arrival.
The fix is to do an interview with your top three or four AEs and ask them one question. Show me the last ten accounts you spent more than four hours on that closed, lost, or churned within twelve months. What was the pattern? The answers turn into negative ICP criteria; you encode the same way you encoded the positive ones. Structured, queryable, weighted to drop accounts below a hard threshold, no matter how well they score otherwise.
ICP without signals is just a description

There is one more layer that the human-grade ICP almost always misses, and it is the layer that turns a static description into a system that knows when to act. It is the signal layer.
An ICP says who your buyer is. A signal says when your buyer is buying. A company can match every firmographic and technographic criterion in your ICP and still not be in market this quarter. The 95-to-5 rule from the Ehrenberg-Bass Institute has been making this point for years. Most of your perfect-fit accounts are not in buying mode at any given moment. The ones that are happen to be in that mode for a reason, and the reason is usually visible if you know where to look.
A new VP of Sales just started. The company shipped a layoff and is rethinking the stack. They closed a Series B and are scaling the team. They posted six new engineering job listings in the last two weeks, targeting your category. A former champion at a different company just took a leadership role here. UserGems, Common Room, 6sense, and Bombora are all built around aggregating these signals at scale. The agent layer is what makes them actually useful, because watching ten signals across a thousand accounts continuously is the kind of work humans cannot do well, and agents can.
The ICP document, in its agent-grade form, has to include the signal section. Which signals matter for our motion. Which signals weight up an account that is borderline on firmographic fit. Which signals are strong enough to override a near-miss on the structured ICP score. Which signals are noise. The agent reads this layer as a configuration, the same way it reads the structured ICP fields.
Skip the signal layer, and your agent ranks accounts well but cannot tell you when to reach out. Add it, and the same agent becomes a system that fires alerts at trigger moments, which is the entire point of running this in real time rather than as a quarterly list refresh.
How we actually run the exercise
When a client asks how long this takes to do well, the honest answer is two to three weeks if you are starting from a real customer base. Less if your product is new and the closed-won data is thin. More if your team has strong opinions and the closed-won data tells a different story than the opinions, which happens roughly half the time.
The shape of the work is the same across engagements. Week one is the closed-won audit. Pull the data, structure it, run the pattern analysis, surface the segments that actually drive revenue and retention. Week two is the negative ICP and the AE interviews. Encode the disqualifiers. Week three is the signal layer and the weighting work. Decide which signals matter, what they are worth, how they interact with the structured criteria, and write the whole thing up as a document the agents can consume.
The output is not a slide deck. It is a structured artifact. The version we ship to clients is usually a JSON or YAML file plus a human-readable companion document, with the ICP fields, weights, signals, and disqualifiers all encoded explicitly. Claude Code reads this directly. Our GTM stack documentation covers how that file plugs into the agent chain.
We do this work before we wire up a single agent. Building the agent infrastructure first and then trying to retrofit the ICP into it is the most expensive way to discover that your ICP is the bottleneck. The architecture only compounds when the inputs are right.
The single most common mistake

If I had to pick one mistake teams make at this stage, it is treating the ICP as a one-time exercise. The ICP for an autonomous pipeline system is a living artifact. The closed-won data updates every quarter. New disqualifiers emerge from lost deals. Signals that mattered last year stop mattering when the buyer landscape shifts. Weights that produced a good ranking when you wrote them produce noise six months later if nothing has been recalibrated.
The teams that get this right treat the ICP file the way engineering teams treat infrastructure-as-code. It lives in version control. It has a changelog. It gets reviewed quarterly against the latest closed-won and closed-lost data. The agents pull from the current version, not the version someone wrote last spring and stuck in a Notion doc.
This sounds like overhead. It is. The overhead is the price of having a system that learns. Without the discipline, the agent system slowly drifts away from the actual business and starts producing a pipeline that looks like the business as it was eighteen months ago. With the discipline, the system gets sharper every quarter, and the gap between your motion and your competitors’ grows.
The honest answer
If you are about to build an autonomous pipeline system and you have not redone your ICP for it, stop and do that first. Two to three weeks of disciplined ICP work will save you three months of agent debugging. The agents are not the hard part. The configuration is the hard part, and the ICP is the most consequential piece of configuration in the entire system.
If you have already built agents and they are not producing the pipeline you expected, the diagnosis usually starts here, too. Most agent system failures look like agent failures and turn out to be ICP failures. The agent did exactly what you told it to. You told them the wrong thing.
Either way, the document you write is the foundation on which everything else sits. Get it right, structured and weighted and signal-aware and falsifiable, and the agents above it will surprise you. Get it wrong, and no amount of model upgrades will save the system.
About Azarian Growth Agency

Azarian Growth Agency is an AI native growth marketing agency working with VC-backed founders, PE operating partners, and growth-stage B2B leadership teams. We build full funnel growth systems anchored on agent infrastructure, with 91 agents in production across client engagements as of 2026.
Our work spans pipeline diagnostics, ICP architecture, decision maker mapping, intent signal infrastructure, and the broader stack of AI content marketing, AI-driven customer insights, and generative AI for marketing. The Strategic Growth Diagnostic is the entry point for most engagements: a structured assessment of pipeline, CAC, signal infrastructure, and agent readiness, framed against the metrics PE and VC institutional buyers actually use.
About the webinar
I run a recurring live demo of the autonomous agent system that the agency builds for B2B clients. The session walks through the full agent handoff in real time, starting from the structured ICP that drives every downstream decision the agents make.
Attendees see the prompts, the data flows, the verification checkpoints, and the metrics framework that ties the motion back to the pipeline and CAC payback. The session is built for VC-backed founders, VPs of Sales, and operating partners evaluating GTM efficiency at the portfolio level.
Check the webinar: Tech Week Boston autonomous agents pipeline session.

