

How to Evaluate a Live AI Pipeline Demo Without Getting Fooled by a Sandbox.docx
Most B2B companies are still trying to fix a pipeline problem with people. The math stopped working in 2023, and nobody told the org chart. 87% of enterprises missed their 2025 revenue targets. CAC payback periods stretched past 50 months at the median. Pipeline coverage sits well below the 4x healthy floor.
The first reaction in most companies is to hire another SDR, sign another data contract, and run the same motion harder. The companies that are actually hitting plan have done something different. They have rebuilt the pipeline function around agent systems, and they have stopped pretending the SDR seat is a fixed cost.
I run Azarian Growth Agency, an AI native growth agency. We have 91+ agents in production across client engagements. The pattern is consistent enough that I no longer treat it as a thesis. Companies that move first on autonomous GTM compress sales cycles, run leaner GTM teams at the same revenue band, and start hitting institutional CAC payback again.
Companies that wait, or that buy an AI SDR without rebuilding the underlying motion, produce zero pipeline. Jason Lemkin watched 20+ SaaStr portfolio companies attempt this and concluded 90% of folks get absolutely nothing. Zero pipeline. Zero meetings.
Want to see this run live?
We are demoing the agent system at Tech Week Boston: check the autonomous agents pipeline webinar.
This is the operator playbook for the other 10%. What outbound sales automation actually means in 2026. The four agent categories that matter. The eight steps to build a working motion. What agents do not replace. And the failure modes I see kill more deployments than every other reason combined.
What autonomous GTM actually means

The phrase has been worn out fast. Most products marketed under it are workflows in disguise. Gartner formally warned in mid 2025 about widespread agent washing, where vendors repackage RPA, chatbots, and AI assistants as agentic systems. Their forecast is that more than 40% of agentic AI projects will be canceled by the end of 2027. That number is going to age accurately.
The cleanest working definition comes from Anthropic’s research on building effective agents. Workflows are systems where models and tools follow predefined code paths. Agents are systems where models dynamically direct their own processes and tool usage, holding control over how they accomplish a task.
In operator terms, an agent has four properties a workflow does not. It plans across multiple steps. It calls tools in a loop, observing results and choosing the next call. It maintains memory across sessions. And it has decision authority inside the guardrails you set.
A Zapier sequence is not an agent. A cadence engine is not an agent. Salesforce Agentforce, HubSpot Breeze, Clay’s Claygent, and UserGems Gem-E are. Marc Benioff named the macro shift at Dreamforce 2025 when he called the agentic enterprise the next revolution after predictive AI. Salesforce backed it with the numbers.
Q4 FY26 Agentforce ARR hit $800M, up 169% year over year. The definition matters because the buying decision matters. If you are evaluating a platform whose agent is really a templated workflow, you are buying 2022 software at 2026 prices.
Why the unit economics flipped
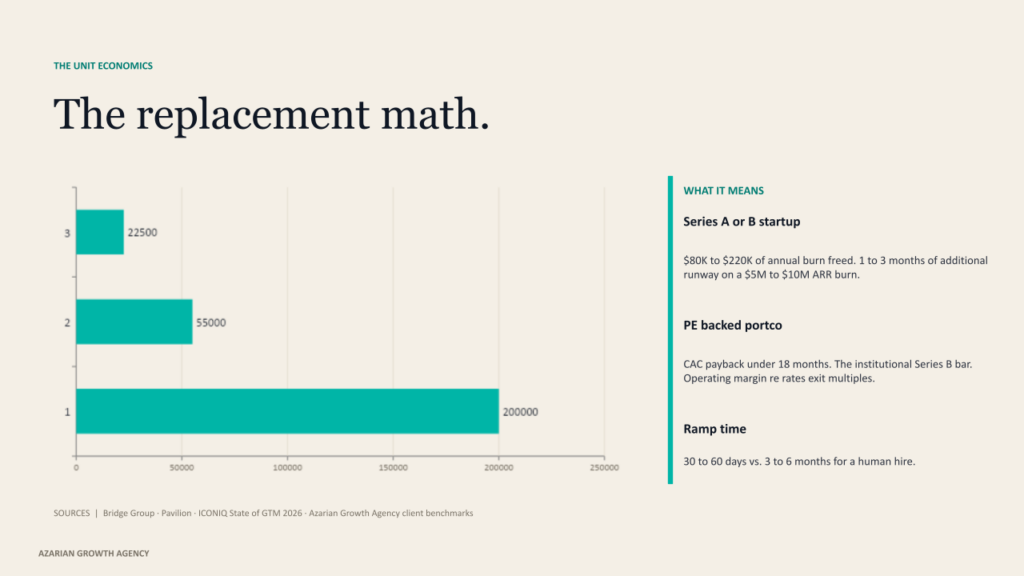
A fully loaded SDR costs $110K to $160K a year. Add tooling and management overhead, and the total cost to the first meeting in the old model lands near $200K. Median ramp is 3.2 months. Annual turnover sits around 39%. Roughly 15 months of productive output per hire, and only about half of SDRs hit quota. None of that is news to anyone who has run a sales org.
An agent stack runs $15K to $150K a year, with most teams landing between $30K and $80K. Ramp is 30 to 60 days. The replacement math is direct. For a Series A or B startup, swapping one or two SDR hires for a $30K to $60K agent stack frees $80K to $220K of annual burn. On a typical $5M to $10M ARR burn rate, that is one to three months of additional runway. CAC payback moves from 30+ months back under 18, which is the institutional bar for Series B in 2025.
For PE-backed portfolio companies, the math is more aggressive. Vista Equity Partners launched its Agentic AI Factory across roughly 90 portcos. Robert Smith said on CNBC in early 2026 that 30 portcos are already generating revenue from agentic AI.
Orlando Bravo at Thoma Bravo framed the EBITDA case at Stanford by saying these companies can now realistically run at 50% margin and 20% growth. That is the operating margin lever rebuilding GTM stacks across the PE world this year.
ICONIQ State of GTM 2026 is the cleanest independent benchmark. AI native GTM teams run 38% leaner at every revenue band. At $10M to $25M revenue, high adopters average 20 GTM FTEs versus 35 at low adopters. Quota attainment hit 62% at high adopters in 2025, the best in three years. We see the same pattern in our own client base. The teams that rebuilt the motion in 2024 are running roughly half the SDR headcount they planned for and producing more pipeline.
The four agent categories you actually need
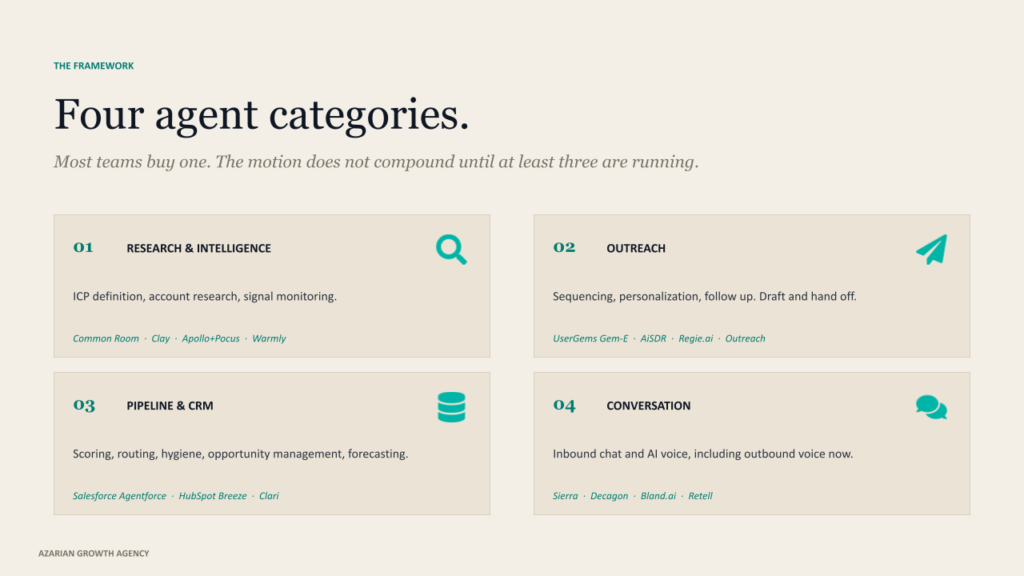
Every working agent stack reduces to four functional categories. Most teams buy one and call it autonomous GTM. The motion does not compound until at least three are running together.
Research and intelligence agents
These define ICP, surface accounts, and monitor signals continuously. The leaders are Common Room for community and product signals, Clay with Claygent for waterfall enrichment across 150+ providers, Apollo after the Pocus acquisition in March 2026, consolidating contact data with PLG signal intelligence, and Warmly for transparent modular pricing. Notion’s published case with Common Room produced a 30% increase in meetings per rep within five months. Use this layer alongside AI research tools for ICP enrichment and AI driven customer insights for closed-loop calibration.
Outreach agents
These handle sequencing, personalization, follow up. UserGems Gem-E, AiSDR, and Regie.ai dominate the pure play category. Apollo and Outreach embed agents into existing seat licenses. The non-negotiable is to avoid vendors that draft and send blindly.
The agents work on the draft and hand it off. They do not autopilot the high-stakes touches. We treat the outreach layer as an extension of our broader AI tools for the email marketing stack, with deliverability infrastructure as a first-class concern.
Pipeline and CRM agents
Scoring, routing, hygiene, opportunity management, forecasting. Salesforce Agentforce 360 released in October 2025, runs through the Atlas Reasoning Engine with multiple pricing models. HubSpot Breeze made the most important pricing move of 2026 in April with outcome-based pricing at $0.50 per resolved conversation and $1.00 per qualified lead. Clari and Salesloft now operate as a combined entity after their late 2025 merger, and tuned forecasting deployments hit 85% to 95% accuracy.
This is also the layer where AI marketing analytics feeds back into the system, so reps and revops are not running parallel dashboards.
Conversation agents
Inbound chat and AI voice. Sierra hit $100M ARR in seven quarters, the fastest in enterprise SaaS history, and is reportedly past $150M ARR with 40% of the Fortune 50 as customers. Decagon raised $250M at a $4.5B valuation in January 2026. Voice infrastructure is now mature. Bland.ai sits near $0.09 per minute, Retell near $0.07.
For high ACV B2B outbound voice, the unit economics that did not work eighteen months ago now work. This is the layer most companies underestimate. AI powered chatbots that resolve real conversations are a different category than the script trees of 2022.
The eight-step build sequence

We sequence client builds in this exact order. Skip a step, and the rest fails. This is the playbook we run when a Series B founder or a PE operating partner asks us to rebuild outbound from scratch.
01. ICP definition with operator-grade rigor.
Most ICPs read like marketing decks. The ones that actually drive an agent stack read like a data model. Build it across four layers. Firmographic. Technographic. Behavioral. Signal-based. For most teams, the realistic target is ten to fifteen tracked attributes, continuously evaluated against closed won data. The compounding move is to retrain on closed losses. Losses are a cheaper signal than wins, and they pull the ICP back from the wishful version that lives in marketing’s head.
02. Signal aggregation and scoring.
First-party signals (your site, your product) sit at the top of the hierarchy. Second party (G2, TrustRadius, marketplaces) comes next, because comparison page visits correlate to roughly two times the average deal size. Third party (Bombora topic intent) is broad but probabilistic and sits last. The mistake teams make is treating these as equal. They are not. Stack them. When a former champion joins a new account, the account has just raised a Series B, and three people there are researching your category on G2 in the same week, your win rate jumps materially. Single signals are noise. Stacked signals are buying behavior.
03. Decision maker mapping with verified contact data.
Bounce rates on the legacy contact databases have crept up. We run waterfall enrichment across multiple providers, then layer email validation before any send. For a human SDR, sending 200 emails a month with a 20% bounce rate is annoying. For an AI agent sending 3,000+ a month, it kills your domain reputation in two weeks. Deliverability is not a side concern. It is the substrate the entire motion runs on.
04. Persona-based message generation, not template-based.
The first name mail merge is dead. So is the version with one personalized opener and a generic body. The agents that produce reply rates above the 3.43% platform wide average reported by Instantly’s 2026 benchmark reference a podcast appearance, a GitHub contribution, a tech stack change, a recent funding round, or an actual content engagement. The signal goes in the body, not the subject line. The signal also has to be readable to a human reviewer in two seconds. If your team cannot tell why a specific message went to a specific person at this specific moment, the personalization is not real.
05. Multi-channel orchestration.
Email plus LinkedIn plus retargeting against the same account, triggered off the same signal, sequenced in the same calendar week. Coordinated multi-channel sequences materially outperform email only. The orchestration discipline that matters is signal-triggered, not calendar-triggered. A sequence that runs on day 1, 3, 7, 14 is a calendar artifact. A sequence that runs when a buying committee member views your pricing page, then your competitor’s review profile, then your ROI calculator, in that order, is an agent system.
06. Human review and routing layer.
This is where most autonomous GTM deployments break. Pure autopilot fails at the message quality threshold every time. Set thresholds. Low signal accounts auto send within tight guardrails. High signal accounts queue for human review. The agents that work are dual-mode by design, autopilot for low-risk follow-ups and copilot for high-stakes touches.
The 10X SDR pattern Florin Tatulea describes is not a person who sends ten times more email. It is a person whose review and judgment is amplified by a research and outreach layer that does the work they used to do manually.
07. Feedback loops and continuous calibration.
The agents that work are the agents that learn. Reply data refines ICP weights. Closed won feedback adjusts signal scoring. A/B testing infrastructure runs automatically on subject lines, opening lines, and signal interpretations. Lemkin describes a SaaStr portfolio company that needed six weeks of daily training to get an AI SDR performing at the level of their top human SDRs. Two hundred plus iterations before it was production-ready. Most teams quit after iteration three.
08. Measurement framework.
Reply rate is a vanity metric. The metrics that compound are meeting held to opportunity conversion, pipeline velocity (opportunities times deal value times win rate, divided by cycle length), pipeline coverage ratio calibrated by ICP tier, and CAC payback. We track these weekly. Teams that track pipeline velocity weekly hit forecast accuracy materially higher than teams running ad hoc. The reason is that velocity exposes problems three weeks before the win rate does.
How to Evaluate a Live AI Pipeline Demo Without Getting Fooled by a Sandbox.docx
What agents do not replace

Agents do not replace trust. They do not replace complex enterprise discovery. They do not replace negotiation, multi-stakeholder consensus, or the hour-long whiteboard session where a champion realizes your product solves a problem they did not know they had. The average B2B purchase involves close to seven decision makers, and most sales teams only engage four or five of them.
An agent can identify the rest. It cannot read the room when a technical evaluator is hesitant to voice concerns in front of their boss. Lemkin’s framing on this is precise. Routine one-to-two call closes are prime for AI deflection, but enterprise B2B sales still require human judgment, relationship building, and strategic thinking that AI does not replicate.
The cautionary tales are public. TechCrunch’s investigation of 11x.ai documented listed customers that were not actually customers, with ZoomInfo’s spokesperson stating the product performed significantly worse than their human SDRs during the pilot. Former employees reported 70% to 80% customer churn.
Artisan’s Stop Hiring Humans campaign drew a LinkedIn ban in early 2026 for scraping and brand policy violations. The lesson is not that AI SDRs do not work. We deploy them every week.
The lesson is that pure autopilot, with no review layer and template grade personalization, will get your domain blocked, your brand damaged, and your prospects burned. AI SDR annual churn runs roughly twice the rate of the human SDRs they were supposed to replace. That number is the market punishing the wrong implementation pattern, not the wrong category.
How real implementations fail
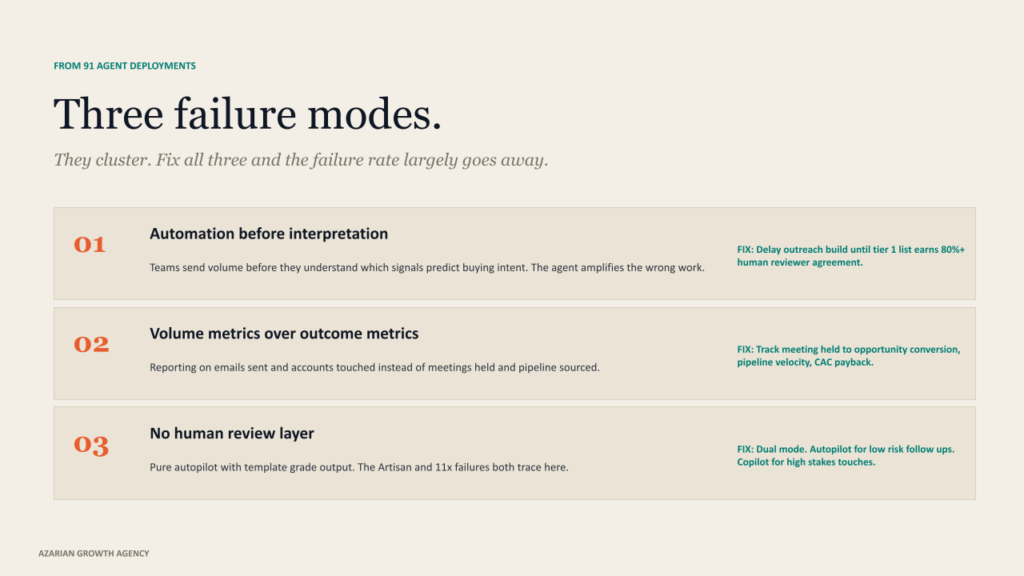
Across our 91 agent deployments, I see the same failure modes repeat. They cluster into three groups.
Building automation before interpretation. Teams send volume before they understand which signals predict buying intent. The result is that the agent amplifies the wrong work. The fix is to delay the outreach build until the signal scoring layer is producing a tier 1 list that a human reviewer agrees with on more than 80% of accounts.
Volume metrics over outcome metrics. Reporting on emails sent and accounts touched instead of meetings held and pipeline sourced. A team with a 4% reply rate and tight qualification will outperform a team with 8% replies and loose criteria every quarter. Volume metrics are addictive because they are easy to move. Outcome metrics are slow because they are honest.
No human review layer. The Artisan and 11x failures both trace here. The signal is fine. The targeting is fine. The message is template grade, and the autopilot is full speed. The cost is your domain reputation and your brand. The pattern that works is dual mode. Autopilot for the bottom of the funnel, where the touches are predictable. Copilot for anything above a defined ACV threshold or anything that involves a champion or executive.
The single counterintuitive lesson from running this every day is that agents need more management than humans, not less. They do not argue back. They follow up exactly when you tell them to. That is the asset and the liability. A human SDR who is given a bad list will push back. An agent will work the list until you stop it.
What changes over the next 12 months
Five concrete shifts to plan around if you are setting next year’s GTM stack today.
Outcome-based pricing becomes the default. HubSpot’s April 2026 move on Breeze is not an outlier. ICONIQ data already shows outcome-based pricing adoption among AI vendors jumping from 2% mid 2025 to 18% by year-end, with more than a third of companies planning to change pricing models in the next twelve months. The CFO conversation has shifted permanently. Paying flat license fees regardless of agent performance is paying for the AI’s failures.
Apollo plus Pocus reshapes the data layer. Apollo absorbed Pocus’s enterprise revenue intelligence in March 2026, moving from execution layer commodity to a data plus signals plus execution platform. Bundled pricing within two quarters is likely. The downstream effect is that point solution intent providers face new pressure on price and on bundling.
Voice agents move into outbound. Sierra’s acquisitions of Receptive AI and Fragment, plus reported ARR past $150M, signal that conversation infrastructure is enterprise-ready. Voice cost per minute under ten cents makes high ACV outbound voice viable for the first time. Expect at least one PE-backed portco to publicly announce 100% AI outbound voice deployment by Q3 2026.
The model layer consolidates around Anthropic. Claude is now the explicit model behind Clay, Common Room, and Salesforce Agentforce 3. The operator implication is that prompt portability across stacks improves, and the agent quality ceiling rises with each model release rather than each platform release.
Adoption gap closes. Kyle Poyar’s 2026 State of AI for GTM found that 47% of teams have no AI agents in production, and only 2% have more than 21 agents running. By Q4 2026, I expect the number of agents to compress under 25%. Gartner’s prediction that AI agents will outnumber human sellers ten to one by 2028 is directionally correct. Companies that move first will rebuild GTM cost structures their competitors cannot match.
The decision in front of you
Outbound sales automation in 2026 is not a buying decision. It is an operating model decision. Buying an AI SDR without rebuilding ICP, signal infrastructure, deliverability, human review, and feedback loops will produce the zero pipeline outcome that 90% of teams produce on their first attempt. We have run this experiment 91 times across client engagements.
The result is consistent. The teams that win do not buy autonomy. They built it, sequenced and instrumented, and managed like a senior hire that costs $30K instead of $150K.
The economic case is now unambiguous. CAC payback under eighteen months. Pipeline coverage is built on signal precision rather than volume blast. GTM headcount running materially leaner than peers. These are no longer aspirational. They are the new institutional bar. The Series A and B founders who hit them keep their runway.
The PE portcos that hit them re rate at exit. The mid-market sales orgs that hit them stop missing quota. The 2026 question is not whether to deploy agents. It is whether you understand the four categories, the eight steps, and the failure modes well enough to deploy them without producing the result that 90% of first attempts produce.
About Azarian Growth Agency

Azarian Growth Agency is an AI native growth marketing agency working with VC-backed founders, PE operating partners, and growth-stage B2B leadership teams. We build full funnel growth systems anchored on agent infrastructure, with 91 agents in production across client engagements as of 2026. Our work spans pipeline diagnostics, intent signal architecture, outbound sales automation, and the broader stack of AI content marketing, AI advertising, and SEO systems.
The Strategic Growth Diagnostic is the entry point for most engagements. It is a structured assessment of pipeline, CAC, signal infrastructure, and agent readiness, framed against the metrics PE and VC institutional buyers actually use.
I run a recurring live demo of the autonomous agent system that the agency builds for B2B clients. The session walks through the three-agent handoff in real time. The TAM and signal scoring agent. The decision maker mapping agent.
The persona and outreach agent. Attendees see the prompts, the data flows, the review checkpoints, and the metrics framework that ties the motion back to the pipeline and CAC payback. The session is built for VC-backed founders, VPs of Sales, and operating partners evaluating GTM efficiency at the portfolio level.
Check it here: Tech Week Boston autonomous agents pipeline session.

